
Part Three: How Appending Works and the StringBuilder Expands
So far in this series, we’ve learned when we should consider using StringBuilder in our code and learned about the memory overhead of using a StringBuilder. It’s now time to learn how the StringBuilder can “expand” its capacity and support appending string data efficiently.
As with the last post, this content is based upon a review of the implementation details of the StringBuilder class and these details may change over time. I have used the current code from .NET 6 while researching this blog post. The design of StringBuilder has changed little in past versions of .NET, so I expect these to remain broadly applicable to earlier .NET versions.
The Mystery of Multiple StringBuilders
Before we dive into the details, I want to address something we observed in the first post in this series where we executed the following code, providing a value of 100 for the iterations.
const string testString = "test string";
var iterations = int.Parse(Console.ReadLine() ?? "0");
var str = new StringBuilder();
for (var i = 0; i < iterations; i++)
{
str.Append(testString);
}
var output = str.ToString();
Through profiling, we observed that the following objects where allocated on the heap.
| Type | Allocated Bytes | Allocated Objects |
| StringBuilder | 384 | 8 |
| String | 2,222 | 1 |
| Char[] | 4,288 | 8 |
| RuntimeType | 40 | 1 |
I promised that we’d come back to the curious number of StringBuilder instances, and so here we are. Why have eight instances been allocated by running this code? We created a single instance before the loop, so we should observe only one, right? The best way to solve this mystery is to investigate what happened when we append data.
Appending String Data
As we learned in the first post, creating a new StringBuilder using the parameterless constructor also creates an array used for the buffer of characters that will later make up the final string. By default, the array is sized to hold 16 characters. That doesn’t sound like a lot, and it’s not, but this is only a starting point and is a low number to avoid large allocations until they are actually necessary.
Let’s investigate what happens as the above code executes and the loop iterates. Our test string is appended to the StringBuilder on the first iteration and starts to fill the array. There are a lot of overloads of the Append method accepting different forms of data to be appended. The Append method executed in this case is as follows.
public StringBuilder Append(string? value)
{
if (value != null)
{
char[] chunkChars = m_ChunkChars;
int chunkLength = m_ChunkLength;
int valueLen = value.Length;
if (((uint)chunkLength + (uint)valueLen) < (uint)chunkChars.Length)
{
if (valueLen <= 2)
{
if (valueLen > 0)
{
chunkChars[chunkLength] = value[0];
}
if (valueLen > 1)
{
chunkChars[chunkLength + 1] = value[1];
}
}
else
{
Buffer.Memmove(
ref Unsafe.Add(ref MemoryMarshal.GetArrayDataReference(chunkChars), chunkLength),
ref value.GetRawStringData(),
(nuint)valueLen);
}
m_ChunkLength = chunkLength + valueLen;
}
else
{
AppendHelper(value);
}
}
return this;
}
When the string is not null, it is appended to the array using specialised code. The first conditional check determines whether the length of the string + the current chunk length (the number of characters already stored) is less than the number of available characters. If so, the string can be appended within the existing character array.
For short strings, one or two characters in length, it stores them into the array via indexers. For longer strings, it calls into Buffer.Memmove, an internal static method. I’ll wave my hands around a lot to distract you from the details since it’s not that important to understand precisely how this works. In short, it uses an optimised native code path to move the characters from the string being appended onto the end of the array buffer. After completing this, the chunk length is incremented as this contains the count of characters in the current chunk.
Our test string is eleven characters, so this can be successfully copied into the buffer. After the memory copy, this leaves five unused slots.
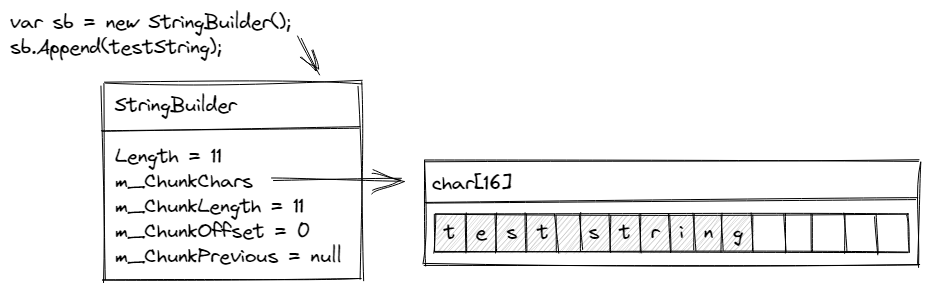
The m_ChunkLength field now reflects that we have 11 characters inside this chunk. The Length property on the StringBuilder also reflects the overall length as 11. m_ChunkPrevious is still null at this stage.
We again end up in the Append method on the second iteration, but this time, the method will calculate that the required number of characters exceeds the chunk length. This results in the AppendHelper method being called.
private void AppendHelper(string value)
{
unsafe
{
fixed (char* valueChars = value)
{
Append(valueChars, value.Length);
}
}
}
This is code which .NET developers will generally not write themselves as it drops into unsafe territory. A pointer to the memory location of the sequence of characters that make up the string is established. The use of the fixed keyword here prevents the .NET garbage collector from moving that memory until the end of the fixed block, pinning it in place. This is important once code starts dealing with low-level pointers as it no longer has the safety of .NET memory management to fall back on. It doesn’t want the managed memory where this pointer points to be moved until it is finished with it. Don’t worry if this is a little unclear, as it’s not crucial to understand the general details of how the StringBuilder works. Honestly, it’s a level of C# I’ve never needed to use myself. After pinning the memory, another Append overload is called.
public unsafe StringBuilder Append(char* value, int valueCount)
{
if (valueCount < 0)
{
throw new ArgumentOutOfRangeException(nameof(valueCount), SR.ArgumentOutOfRange_NegativeCount);
}
int newLength = Length + valueCount;
if (newLength > m_MaxCapacity || newLength < valueCount)
{
throw new ArgumentOutOfRangeException(nameof(valueCount), SR.ArgumentOutOfRange_LengthGreaterThanCapacity);
}
int newIndex = valueCount + m_ChunkLength;
if (newIndex <= m_ChunkChars.Length)
{
new ReadOnlySpan<char>(value, valueCount).CopyTo(m_ChunkChars.AsSpan(m_ChunkLength));
m_ChunkLength = newIndex;
}
else
{
// Copy the first chunk
int firstLength = m_ChunkChars.Length - m_ChunkLength;
if (firstLength > 0)
{
new ReadOnlySpan<char>(value, firstLength).CopyTo(m_ChunkChars.AsSpan(m_ChunkLength));
m_ChunkLength = m_ChunkChars.Length;
}
// Expand the builder to add another chunk.
int restLength = valueCount - firstLength;
ExpandByABlock(restLength);
Debug.Assert(m_ChunkLength == 0, "A new block was not created.");
// Copy the second chunk
new ReadOnlySpan<char>(value + firstLength, restLength).CopyTo(m_ChunkChars);
m_ChunkLength = restLength;
}
AssertInvariants();
return this;
}
The method accepts a char pointer and a valueCount, the number of characters to be appended. Inside this method, a few checks occur such as insuring that the valueCount is greater than zero. The code then calculates the new length, which is the current Length of the StringBuilder plus the valueCount. If this newLength is greater than the m_MaxCapacity field, an ArgumentOutOfRangeException is thrown. The m_MaxCapacity field allows us to define the maximum number of characters a StringBuilder should support, and this defaults to int.MaxValue.
Assuming these checks pass, the data is ready to be copied into the StringBuilder. A newIndex value is calculated, which is the valueCount plus the m_ChunkLength field value. Remember that m_ChunkLength represents the number of characters stored inside the current chunk. In our example, the value of newIndex is 22. If this value is less than the array’s length, an optimised Span<T> based copy is performed, and the chunk length updated. In our example, this is not the case, so the execution enters the else block.
This code calculates how much space the current array has available. If there is any space, a ReadOnlySpan<char> is created over the memory specified by the char pointer for a specified number of char elements. In our case, this will be a ReadOnlySpan over the first 5 characters of the string being appended. The characters are then copied into the m_ChunkChars array, filling the remaining capacity. This, of course, leaves us some characters which are yet to be written. At this point, our StringBuilder looks like this.
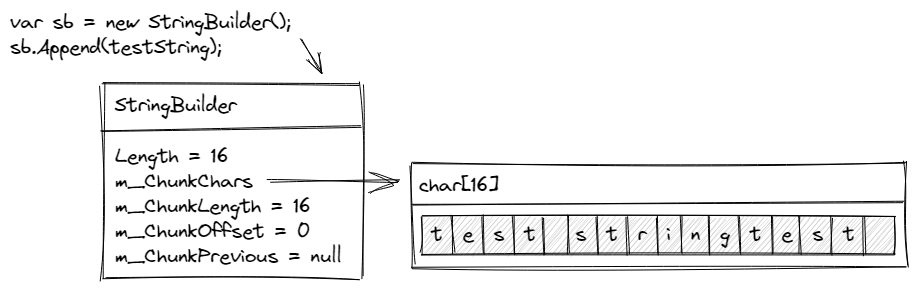
The array used by this StringBuilder is now full.
Next, the length of the remaining characters is calculated, and the StringBuilder is ready to expand by adding another chunk. This is achieved by calling the ExpandByABlock method, passing the required capacity to it as the minBlockCharCount. Once the new chunk is ready, the remaining data from the current char pointer will be copied into the buffer, which will be the string starting from the 6th character. Before we focus on that, let’s dig into what ExpandByABlock is doing.
private void ExpandByABlock(int minBlockCharCount)
{
Debug.Assert(Capacity == Length, nameof(ExpandByABlock) + " should only be called when there is no space left.");
Debug.Assert(minBlockCharCount > 0);
AssertInvariants();
if ((minBlockCharCount + Length) > m_MaxCapacity || minBlockCharCount + Length < minBlockCharCount)
{
throw new ArgumentOutOfRangeException("requiredLength", SR.ArgumentOutOfRange_SmallCapacity);
}
int newBlockLength = Math.Max(minBlockCharCount, Math.Min(Length, MaxChunkSize));
if (m_ChunkOffset + m_ChunkLength + newBlockLength < newBlockLength)
{
throw new OutOfMemoryException();
}
char[] chunkChars = GC.AllocateUninitializedArray<char>(newBlockLength);
m_ChunkPrevious = new StringBuilder(this);
m_ChunkOffset += m_ChunkLength;
m_ChunkLength = 0;
m_ChunkChars = chunkChars;
AssertInvariants();
}
A few assertions are made when debugging, which aren’t important for this post. We’re interested in how the expansion occurs. The first important line is:
int newBlockLength = Math.Max(minBlockCharCount, Math.Min(Length, MaxChunkSize));
This calculates the length for the new block (aka chunk), which must be at least as large as the minBlockCharCount. This code prefers that the new length is at least as large as the current overall length of the StringBuilder, 16 in our example.
This generally results in each chunk doubling the current StringBuilder capacity on each expansion. Notably, the chunk is generally never made larger than MaxChunkSize, an internal constant value set at 8000. This value ensures that the array used for the new chunk is never large enough to end up in the large object heap (LOH) which would require a full garbage collection (GC) to reclaim. Comments in the code also explain that this value is a balance between lots of smaller allocations vs. wasted space and slower insert and replace calls due to having more data to shift.
The only time where the array may be larger is when an extremely long strong is appended. In that case, minBlockCharCount, i.e. the length of the remaining characters needed to complete the append operation, will be the largest value and used for the array size. It’s worth keeping this in mind when you append long strings, as it could potentially introduce another LOH allocation.
Once the new block size is determined, a check is made to ensure that an integer overflow for the calculated new length has not occurred.
The code is now ready to allocate a new array of the desired length for the new chunk.
char[] chunkChars = GC.AllocateUninitializedArray<char>(newBlockLength);
The GC.AllocateUninitializedArray method is used, a performance optimisation that avoids zeroing the memory used by the array. When initialising larger arrays, this can save precious time but does require careful use to ensure only elements written to by the StringBuilder code are ever accessed. Until an element is written, that memory may contain other data.
The code then performs a small juggling act to copy some values and build up the linked list of StringBuilder instances. First, a new StringBuilder is created using a private constructor.
private StringBuilder(StringBuilder from)
{
m_ChunkLength = from.m_ChunkLength;
m_ChunkOffset = from.m_ChunkOffset;
m_ChunkChars = from.m_ChunkChars;
m_ChunkPrevious = from.m_ChunkPrevious;
m_MaxCapacity = from.m_MaxCapacity;
AssertInvariants();
}
This constructor accepts an existing StringBuilder instance from which the current fields will be copied. This essentially gives us a duplicate StringBuilder with the current character buffer. After the constructor returns, the reference to the new StringBuilder is stored into the m_ChunkPrevious field of the original StringBuilder. This produces the first link in the linked list of StringBuilders.
Finally, a few fields in the current StringBuilder are updated since this now forms the second chunk. First, the offset is increased by the current chunk length. The chunk length is then zeroed since this new chunk contains no data yet. Then the new array is stored into the m_ChunkChars field, ready to be written to. At this point, we’ve created a chain of two StringBuilder instances.
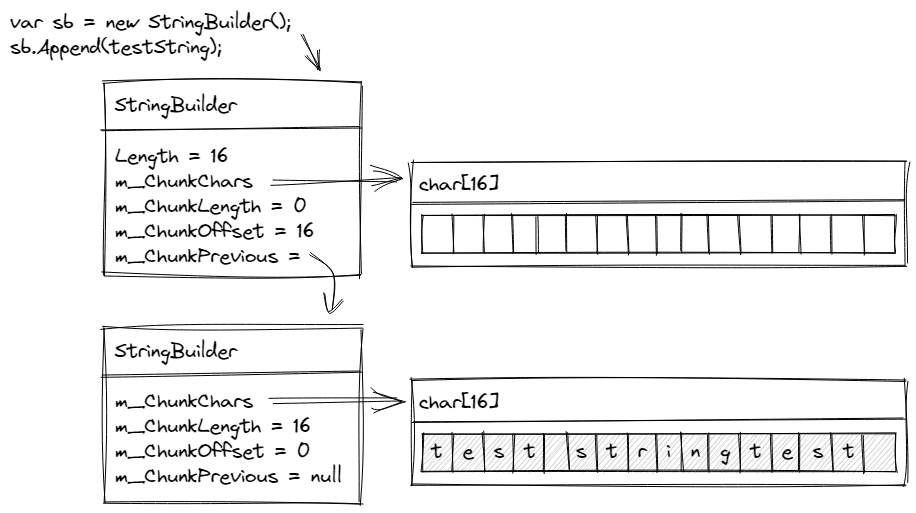
The user code still points at the original instance, which now represents the second chunk of data and maintains a reference to the original chunk in the m_ChunkPrevious field. That original chunk is a StringBuilder into which we copied the existing character buffer.
The new array is sized at 16 elements and at this point is empty. Once the ExpandByABlock method returns, a new ReadOnlySpan<char> is created over the memory representing the un-appended characters. These are then copied into the new array to begin filling this second chunk of data.
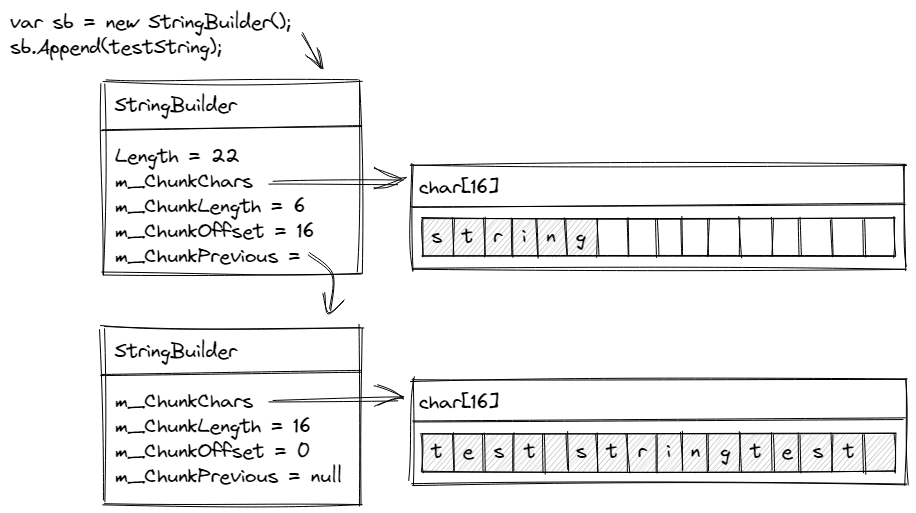
After this gymnastics, we have a new, larger buffer in the original StringBuilder that our code references. We have a reference to the previous chunk, which includes our original buffer.
This process continues on each iteration. Each new chunk at least doubles by the length of all characters currently in the StringBuilder, up to a maximum length of 8,000. It may take further append operations to fill it before causing another expansion with another new chunk. After our append loop completes, we can view the relevant memory traffic as follows.
| Object | Bytes | Retained Bytes |
| StringBuilder | 48 | 104 |
| StringBuilder | 48 | 208 |
| StringBuilder | 48 | 344 |
| StringBuilder | 48 | 544 |
| StringBuilder | 48 | 872 |
| StringBuilder | 48 | 1,456 |
| StringBuilder | 48 | 2,552 |
| StringBuilder | 48 | 4,672 |
| Char[16] | 56 | 56 |
| Char[16] | 56 | 56 |
| Char[32] | 88 | 88 |
| Char[64] | 152 | 152 |
| Char[128] | 280 | 280 |
| Char[256] | 536 | 536 |
| Char[512] | 1,048 | 1,048 |
| Char[1024] | 2,072 | 2,072 |
| String (Length 1,110) | 2,222 | 2,222 |
| RuntimeType | 40 | 40 |
We end up with eight StringBuilders in the linked list, each with its own character array into which data from that chunk is stored. Viewing the allocated arrays, we can clearly see the doubling effect in action.
One question you may have is about that small 40-byte RuntimeType allocation. This is caused on the first call to GC.AllocateUninitializedArray when the required size is 1,024 or greater, which uses typeof(T[]) to access its TypeHandle. This specific detail is not important here and is just a small overhead of the internal machinery.
For comparison, if we re-run our code, this time with 2,000 iterations, we can observe that at a certain point, the char arrays max out at 8000 characters.
| Object | Bytes | Retained Bytes |
| Char[16] | 56 | 56 |
| Char[16] | 56 | 56 |
| Char[32] | 88 | 88 |
| Char[64] | 152 | 152 |
| Char[128] | 280 | 280 |
| Char[256] | 536 | 536 |
| Char[512] | 1,048 | 1,048 |
| Char[1024] | 2,072 | 2,072 |
| Char[2048] | 4,120 | 4,120 |
| Char[4096] | 8,216 | 8,216 |
| Char[8000] | 16,024 | 16,024 |
| Char[8000] | 16,024 | 16,024 |
Summary
That’s probably enough for this blog post which has explored the internal code quite deeply to understand how a StringBuilder “expands” to accommodate more data as it is appended. We learned that data is copied in optimised paths as long as the current chunk has the capacity for the new string data. Once the capacity is reached, a new chunk is created, forming a linked list of StringBuilder instances. Our code does not need to be too aware of this behaviour for general use. However, as we’ll start to investigate in the next post (coming soon), it’s possible to optimise the use of a StringBuilder in certain situations. We’ll learn how to achieve this, and our understanding of these internal details will allow us to understand why such optimisations positively affect performance.
If you want to learn more about using strings in C# .NET applications, please check out my course on Pluralsight.
Other posts in this series:
Have you enjoyed this post and found it useful? If so, please consider supporting me: