This post continues my series about writing high-performance C# code. In this post, we’ll continue from the last two posts by introducing the Span<T> type and refactor some existing code by converting it to a Span-based version. We’ll use Benchmark.NET to compare the methods and validate whether our changes have improved the code.
If you want to follow along the sample code can be found on GitHub.
What is Span<T>?
Span<T> is a new type introduced with C#7.2 and supported in the .NET Core 2.1 runtime. There is a .NET Standard implementation for existing .NET standard 1.0 runtimes but in .NET Core, which is where I’ll focus, runtime changes were made to support the best possible version known also as “fast span”.
Span<T> provides type-safe access to a contiguous area of memory. This memory can be located on the heap, the stack or even be formed of unmanaged memory. Span<T> has a related type ReadOnlySpan<T> which provides a read-only view of in-memory data. The ReadOnlySpan can be used to view the memory occupied by an immutable type like a String for example. I prefer to think of Span<T> as a window into some existing memory, regardless of where it has been allocated.
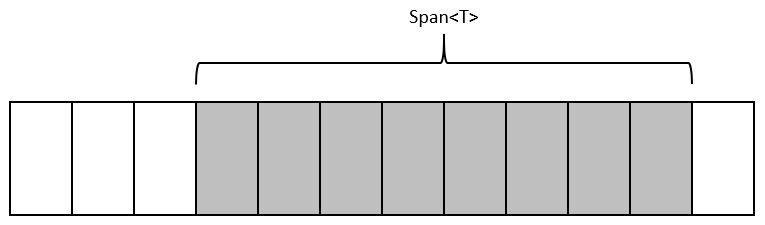
In the diagram above, Span<T> references some contiguous memory that has already been allocated. We now have a window over that memory.
Span<T> is defined as a ref struct, which means it is limited to being allocated only on the Stack. This reduces some potential use cases such as storing it as a field in a class or using it in async methods. These limitations can be worked around by using a similar new type Memory<T> which we’ll look at in a future post. The main reason for the ref struct design is to ensure that when using Span<T> we cause no additional heap allocations. This is one of the reasons it supports such highly optimised use cases in high-performance code paths.
I’ll steer clear of going into too much implementation detail for this post (it is an introduction after all) and instead focus on an example of where we might want to use it and how it impacts our benchmarks.
If you want to read more detail about span I recommend the following links:
- Span<T> Struct
- All About Span: Exploring a New .NET Mainstay
- C# 7.2: Understanding Span
- Span by Adam Sitnik
Improving Speed and Reducing Allocations in Existing Code
In the last post, we benchmarked some code which was used to “parse” out the surname from a full name string. With benchmark.NET we identified that this method took 125.8 ns to run and allocated 160 bytes per run.
Before I move onto a Span<T> based approach, I want this to be a fair fight, so I’m going to first optimise the code without using Span<T>. This will hopefully serve as a good example since it highlights that even without resorting to new features like Span<T>, existing code can be optimised by putting a little thought into what it’s doing.
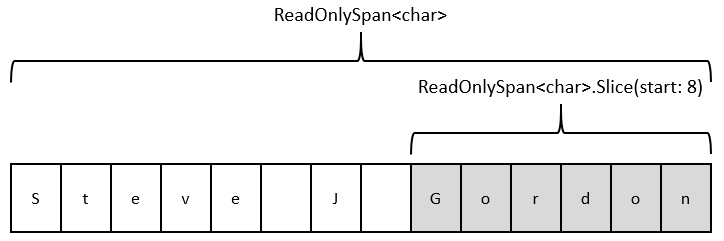
The current code splits the string on any spaces. This results in an array of the constituent string parts. If we consider this, we’re allocating an array and in the case of the name “Steve J Gordon”, we’re allocating three smaller strings of “Steve”, “J” and “Gordon” when we do this. As we’ve seen in our benchmark this causes 160 bytes of allocations.
For the requirement of finding the last name, we don’t care about storing all parts of the name, just the last part which we expect to be the surname. Note that I’m ignoring cases such as multi-word surnames for this example!
Let’s add another method to the NameParser which instead of splitting the string, gets the index of the last space character and uses that to get the substring representing the surname.
First, we get the index of the last occurrence of a space in the full name string. If this is -1, we didn’t find any spaces so we’ll return an empty string as our default result.
If we do find the index, we use the Substring method to extract the last name and return it.
We’ll include this version in our benchmarks a little later on. In reality, though, it’s worth testing each iteration of code improvements as you make them in order to validate whether you are improving things or making them worse.
Using Span<T>
Let’s look at how we might re-write this code again, this time using Span<T>. In very hot paths, where high-performance is really important we want both speed and to reduce memory allocations in our code.
The first thing to note is that the method parameter “fullName” is now of type ReadOnlySpan<char>. Certain types such as strings can be implicitly converted to a ReadOnlySpan of chars, so this method signature will work just fine.
The return type is now also a ReadOnlySpan<char>.
First, in a very similar way to the optimised code above, we look for the last index of the space character.
Again, if this has a value of -1 then we didn’t find a space and we’ll return an empty ReadOnlySpan<char> result.
If we do find a space character, we can now use a feature of Span called slicing.
Slicing is a really powerful operation where we can take an existing Span and “Slice” into a tighter window. When slicing, we specify the index of the start position for the slice and optionally the length of the end position for the slice. Omitting the length results in a slice from the start position until the end of the Span.
Slicing is a low-cost operation as we’re not copying anything, we’re just creating a new Span which represents a window into a subset of an existing memory range.
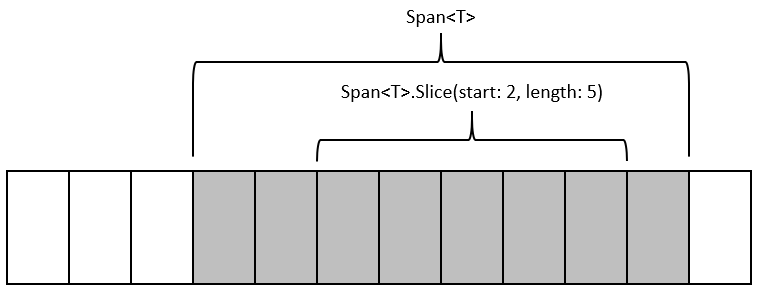
In the diagram above we can create a Slice of the original Span to view 5 elements within it, without allocating any additional copies of the original memory.
In the new Span-based code, we take a slice of the fullName starting at the index after the space character. As we don’t specify a length, this slice will run to the end of the existing Span.
Once we’ve sliced the Span, which results in a new Span over the sliced portion, we return that as the result of the method.
At this point, we have two potential different versions of our improved code, one using Substring and one using Span<T>. Let’s update the benchmarks and compare the results.
Benchmarking the Improvements
After adding two new benchmarks the benchmark class now looks like this:
We have three benchmarks defined, each exercising a different method in our NameParser.
Running the benchmarks gives the following results on my machine…
The last item in this list is our original GetLastName method. Because we asked for ranked results and this method runs the slowest it’s shown last.
This time around it took 125ns to run and of course still allocates 160 bytes.
The second fastest is our attempt at improving the code without Span<T>, which uses Substring. This code is around 3 times faster than the original approach. Significantly, we’ve reduced allocations to only 40 bytes now. This accounts for the surname string we’re allocating when calling substring.
The overall winner though is the Span<T> based approach. This runs 10 times quicker than our original code and 2.8 times quicker than the Substring based approach.
The really important thing here is that because we are slicing into the Span to find the position of the last name and we’re also returning a Span as the output of the method, we’re never allocating a new string. This is evident by the allocated memory stat which is now empty.
For a single call, 160 bytes saved (or 40 bytes against the substring approach) is not huge but on hot paths, the saving adds up. If this code needed to run in a data processing service I maintain that operates on around 20 million messages per day, we would save 3.2 Gigabytes of allocations per day. These are likely to be short-lived allocations, but even so, they will cause garbage collections. Based on the estimated Gen 0/1k operations figure, the original code would trigger 506 GCs per day, on 20 million operations. That’s CPU time and pauses we can help reduce by avoiding any allocations.
Summary
In this post, we looked at the new Span<T> type and used it to refactor some code for optimal performance. Initially, Span can sound a little complex but as I hope I’ve shown, using it in this example was quite straight-forward.
Thanks for reading! If you’d like to read more about high-performance .NET and C# code, you can see my full blog post series here.
Have you enjoyed this post and found it useful? If so, please consider supporting me: