
In this post, I want to explore a new feature of .NET Core 3.0, which simplifies working with a ReadOnlySequence. You may find yourself using a ReadOnlySequence if you work with a PipeReader from System.IO.Pipelines. Before .NET Core 3.0, one would need to manually slice through the ReadOnlySequence from the Buffer property on the ReadResult. With SequenceReader, we can simplify these tasks and let the framework do some of the repetitive work for us in the most optimal way.
At the time of writing, SequenceReader isn’t documented anywhere, so I wanted to cover an example use case here to help people get started. We won’t touch the entire API surface, but hopefully, there’s enough here to get you up to speed with the core functionality.
What is a ReadOnlySequence?
It’s probably worth addressing this question first since this is a reasonably new type in .NET Core and there are limited cases where you’ll come across it.
Some time ago, the Span<T> and Memory<T> types where added. These both support working with continuous regions of memory of various types, through consistent APIs. Since then, many new constructs have built upon the foundation that these types provide. One such example is System.IO.Pipelines which is a high-performance API for dealing with IO.
Traditionally, streams were used for many IO operations. A problem with streams is that they leave you in charge of managing the buffers and copying data between them. Pipelines helps in both cases, by handling the buffers for you internally, exposing the memory without copying where possible. At a simplified conceptual level, the pipe requests some memory from the memory pool, which it then manages, allowing data written to the pipe to be stored in the memory and then read from it. If we know the content length up-front, this simple approach will work very well, but often we don’t know the amount of data which will be written in advance.
Therefore, pipelines relies on the concept of a sequence of memory segments. This is exposed by the PipeReader as a ReadOnlySequence<T>. This is essentially just a linked list of Memory<T> instances. When data is first written, a single Memory<T> buffer is used. If that fills up, then a new Memory<T> segment can be requested. The writing of data can continue into that second segment. Whilst each Memory<T> instance is a contiguous region of memory; each instance will likely refer to different regions in memory. To access the memory across these Memory<T> segments, a sequence is formed which links them together in the correct order.
With this sequence, we now have a virtual contiguous block of memory that we can read through.
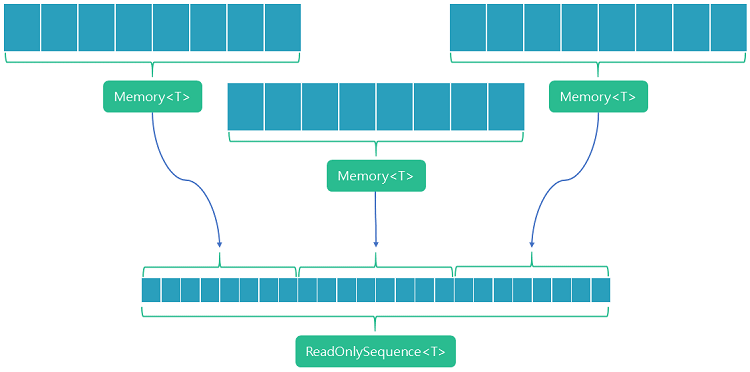
In this diagram, we have three contiguous blocks of memory referenced via Memory<T>. These can exist in three different memory locations. The ReadOnlySequence logically combines these so that the data can be consumed across the segments.
Introducing the Sample Scenario
I’ll be using a simple sample to demonstrate the use of SequenceReader for the remainder of this post. You can find the complete sample code in my GitHub repository.
NOTE: This sample is simplified and skips some steps that you may want to apply when working with pipelines and a ReadOnlySequence. The focus here is on looking at the SequenceReader API and not about ultimate performance optimisation. We can revisit that in a future post and touch on some things we might do to enhance this sample to deal with cases when the sequence contains a single segment, for example.
The scenario here is that we have a Stream of bytes that we know contains UTF8 data which is a comma-separated list of values. In this case, I’ve built the stream manually, but a real-world scenario would be receiving these bytes from an HTTP endpoint. In that case, you’d likely get the content stream from the HttpResponseMessage. The setup code is contained within the ‘CreateStreamOfItems method’. I won’t show that code here as it’s not too crucial to describe the SequenceReader API. You can view it in the GitHub repo if you’re interested.
Working with the PipeReader
Now that we have a stream, we want to work with it via the Pipelines feature. In .NET Core 3.0, convenience methods have been introduced to make converting a stream to a PipeReader trivial.
PipeReader now includes a static factory method called Create which accepts a stream and optionally a StreamPipeReaderOptions. We can pass in our sample stream. For this demo, I’m passing in a StreamPipeReaderOptions which sets a small buffer size. This is not required and is used in this demo to ensure we don’t get the entire stream of bytes back in a single buffer. This allows us to demonstrate the approach of reading portions of the pipe as distinct sequences which span Memory buffers. Again, you don’t need to do this in production, and the defaults are probably going to be okay.
The remaining code in the Main method deals with reading from the pipe.
We use an infinite loop that we’ll break out of once the pipe has been fully read. To begin reading, we can call ReadAsync on the PipeReader which returns a ReadResult. Within the ReadResult, we can access the Buffer property. This gives us our ReadOnlySequence. I pass that into a method called ‘ReadItems’ which we’ll explore more deeply in a moment. We also pass in a bool indicating if the result IsCompleted, which would indicate we have the last of the data from the pipe in the buffer.
We use this bool to break from the loop after the last of the data has been processed. In cases where there is still more data, we advance the PipeReader. This method takes the consumed SequencePosition, which is the position of the bytes we’ve been able to read and use successfully. It also takes the examined SequencePosition, which indicates what we’ve read but not yet consumed. We may have a buffer which contains an incomplete item so while we can examine that data, we won’t be able to use it until we have the complete item. Buffers holding consumed bytes can be released once all of the data is consumed. Buffers holding examined data remain available so that on the next pass, once we’ve read more data into the internal buffer(s), we can hopefully process the now complete item.
When we exit this loop having read all of the data, we mark the PipeReader as complete.
Using SequenceReader<T>
Finally, we’ve reached the main focus of this blog post! Let’s look at how the SequenceReader can help consume the ReadOnlySequence.
I’ve factored the majority of the code into a method called ‘ReadItems’. There are two reasons for this. First, it breaks up the code in more readable units, which I prefer. Secondly, and most importantly, we have to do this for this demo.
The SequenceReader type, like Span<T>, is a ref struct, which comes with some limitations about its use. One of those limitations is that it cannot be a method parameter of async methods or lambda expressions. The reason it needs to be defined as a ref struct is that internally it has ReadOnlySpan<T> properties and this forces the cascade of the ref struct rule that instances can only ever be stored on the stack; not the heap.
My ‘Main’ method is async and therefore I can’t use a SequenceReader directly there. Instead, by factoring the code into a non-async method, we can now use SequenceReader and call this synchronous method from the asynchronous one.
Let’s explore the code…
We start by creating a SequenceReader, passing in the current ReadOnlySequence.
We begin a loop which will exit if the reader.End property is true. This will be the case when there is no more data left to be consumed from the sequence.
Various methods exist on the SequenceReader to support reading and/or advancing through the sequence. We can use the TryReadTo method to attempt to read data up to a given delimiter. In this case, we’re parsing through comma-separated data, so we provide the byte of a comma as the delimiter argument.
If the provided delimiter is found within the sequence, the out parameter will contain the ReadOnlySpan up to (but not including) the delimiter from the current position. In this demo, this will be the bytes for an item. By default, TryReadTo will also advance the sequence reader position past the delimiter, but this can be controlled with the advancePastDelimiter argument.
When TryReadTo returns true, it indicates that the reader found a delimiter and we now have the bytes in the itemBytes variable. We can now work with those bytes. For this simple demo, we’ll convert them to a string and write that to the console.
TryReadTo will return false when the byte value for the delimiter is not found in the sequence. This may occur in one of two cases.
It’s possible that the Pipe now contains all of the available data and the PipeWriter is completed. In this case, all of the remaining bytes will exist in the ReadResult buffer. When that is the case, the ReadResult.IsCompleted property will be true. Our method accepts this as an argument so we can handle this special case.
Since the last item in our data will not include a comma delimiter after it, we need to handle the data a little differently. Our position in the sequence will be at the start of the item, so we can assume that the remaining bytes represent the whole item. We have a separate private method to handle this remaining data, called ‘ReadLastItem’. We pass the current sequence to this method, slicing it from the current position to ensure we are only passing the remaining, unprocessed bytes.
A a high level, this method copies the remaining bytes from the sequence into a temporary buffer which can then be used to get the string representation of those bytes. The ‘ReadLastItem’ method achieves this using two potential approaches.
The expected case is that we avoid any heap allocations by using a temporary buffer for the bytes which is created on the stack. This is possible, thanks to Span which supports referencing stack memory in a safe way. Since working on the stack has some risks around reaching the stack memory limit, we ensure that the length of the remaining bytes is less than our safe limit of 128. With our sample data, we know this to be true, but we should never assume that something won’t change, especially in a real-world case when retrieving this data from an external endpoint.
The second flow which occurs only if the length of the data is beyond our stack safe limit. It uses the ArrayPool to get a temporary byte buffer. This also avoids allocations since we’re using a pool of re-usable arrays. It’s slightly less performant than the stack approach but still pretty efficient overall. We rent an array which will have a capacity at least as large as the length of the bytes we have in the sequence. Be aware that the array is likely to be larger than we require.
In both cases, we can copy the bytes from the sequence using the CopyTo method into the temporary buffer. We then use the Encoding.UTF8.GetString method to convert the bytes to a string representation. In the case of the ArrayPool code path, we must ensure we slice our array to the correct length since the ArrayPool has likely returned us an array longer than our data. We don’t want to try and convert bytes beyond those that we’ve copied in.
The ‘ReadLastItem’ method returns the string value for the final item. Back in the ReadItems method, this string is written to the console. The reader is then advanced by the length of the sequence. This should put us at the end of the sequence, which will cause the while loop to exit. We could just as easily used the break keyword here, but I wanted to demonstrate the Advance method on the reader.
Getting back to the conditions around the TryReadTo call, the second possibility is that, the currently buffered bytes from the PipeReader include an incomplete item. In our case, we could, for example, have the bytes representing “Ite” at the end of the sequence. Until the PipeReader has buffered the remainder of the item, we can’t do anything with this partial item. In this case, we hit the last conditional block and break from the while loop. The ‘ReadItems’ method returns the current SequencePosition that the SequenceReader has reached within the sequence. Remember, only once we’ve successfully read a complete item is the position within the sequence advanced. In this situation, the position will indicate the start of the incomplete item that we have found in the sequence.
‘ReadItems’ returns back to the while loop where we are reading from the PipeReader. This loop continues until all of the data from the Pipe has been consumed successfully.
Summary
I think that’s an excellent place to end this post. We’ve explored some of the newer APIs in .NET Core 3.0 as well as taking an opportunity to look at System.IO.Pipelines and the new stream connector that makes it easy to take a stream and work with it via a PipeReader. Unless you do a lot of IO work, you may never find yourself using Pipelines, and therefore the ReadOnlySequence and SequenceReader may not be types that you use either.
SequenceReader makes consuming the ReadOnlySequence from a PipeReader quite straightforward for this sample case. If you want to work with byte data efficiently, parsing it with as few allocations as possible, Pipelines and the SequenceReader combine to make this possible. I’d be interested to see other examples of use cases and approaches which leverage SequenceReader.
Have you enjoyed this post and found it useful? If so, please consider supporting me: