
At Madgex, we are currently building out v6 of our world-leading job board software. With v6, we are breaking the monolith and applying a microservices architecture. This architecture supports rapid growth of our platform, the introduction of new features, and the adoption of the latest technologies such as .NET Core 3.1, Vue.JS and GraphQL. This post is not intended to be a discussion about the pros and cons of microservices, though. I would like to focus in on a recent piece of work, describing how we used a cloud-native, microservices architecture to meet the feature objectives.
Understanding the Requirement
Our current platform supports multiple tenants, each of whom may configure their job boards to meet the needs of their business. One area that commonly requires configuration is the taxonomy used to categorise the jobs listed on the board. Our v5 platform uses several database tables and configuration files to store information about the configured taxonomy, as well as for localisation and holding metadata used by the platform. A taxonomy is comprised of a collection of categories, each containing a hierarchy of related terms. Beyond that, it’s not essential to go deep into how taxonomy works, let’s just agree that the taxonomy data is owned by the v5 platform (today). There is a fair amount of business logic involved in accessing and interpreting the data.
As a general requirement, we needed a solution for accessing this data from the new v6 services, each of which may have different requirements for that data. More specifically, for a service I was developing, I needed to access specific parts of the taxonomy data. My service is used to expand data recorded as metrics for our Insights analytics platform. A metric from v6 arrives, carrying the minimal data about the event which took place. For example, if a user views a job, we record a job view metric, along with the ID of the job that was viewed.
One of my services, known as the “metric expansion processor”, takes these “lightweight” metrics and expands them to construct a richer, full metric. This requires HTTP calls several new v6 APIs to load additional data which is used in the expansion of the dimensions. For a job view, we load data about the job, including the title, recruiter information, go-live date and any category and terms it appears under. The job data I consume comes from a graphQL API. As part of the payload, I can request the taxonomy data for the job. The response then includes an array of categories and their terms as follows:
The data from the API only includes category and terms IDs. I need to record the metrics using the actual names of the category and term in the format: {category name}:{term name}.
I, therefore, required a further source for the taxonomy data. In the future, this will become easier. We plan to migrate the taxonomy feature into its own service which can likely expose an endpoint to request this data. For now, though, our only source for the data is the v5 application. A core principle in the migration is to avoid coupling new services to the existing platform wherever possible. One option would be to expose an internal endpoint we can call from v6 services to get the taxonomy data. We wanted to avoid that since it requires changes to v5 and also adds request load to the existing v5 application.
The first design decision, owned by another team, was how to provide access to taxonomy data outside of the main platform. Since taxonomy data rarely changes and for various legacy reasons it is often tied to a release, the team added a post-deployment step to the build pipeline. This new step calls back into the newly deployed application, retrieving the taxonomy data in a JSON format and then stores a copy into AWS S3. Amazon S3 (Simple Storage Service) is a managed object (blob) store. The data changes very infrequently, so the retrieved taxonomy is hashed and only uploaded if the data has changed since the most recently stored version.
An example of the JSON file produced by this deployment step and uploaded to S3 is as follows:
This is a massively cut-down example of a full taxonomy file but should provide a depiction of the input data we have to work with. Each category, along with some metadata about it, is represented in an array. Each category may have zero or more terms associated with it. A term can also have zero or more child terms below it in the hierarchy. To support localisation of job boards, each category and term includes names (and paths) for any supported cultures.
Architecture Design
We’ll pick up from this point to review the high-level architecture I elected to use for the remainder of the system. As with all software projects, there are often numerous choices for implementation.
The first decision was how best to use the JSON taxonomy data. My service required a limited subset of the taxonomy data, used to convert from term IDs returned by the Jobs API, to string representations used on the enriched metrics. There were a few options at this stage. One was to simply load the appropriate JSON file for each client when enriching metrics for a job. Since the file is JSON, we could potentially have parsed it for the values we needed on a job-by-job basis. I ruled this out since parsing the large file over and over, seemed like a waste. Since we only needed a small subset of the data, I instead favoured the idea of building a projection.
This follows the concept of event sourcing, where we use events to signal state change, consuming those to maintain a data projection. The benefit of this is that the projection can use a schema containing only the required properties. Our service will own the projection containing the data only it needs. Additionally, we can update the schema based on events, limiting the repetition of re-parsing data that has not changed. One side effect of such a design is the eventual consistency of the projection. Changes to taxonomy require a few actions before the projection is updated, meaning that the projection may be slightly out of step with the taxonomy for a tiny window of time. In our case, this wasn’t a big issue, and our services could accept this trade-off.
Since we’re hosted on AWS, I wanted to leverage some of the managed features which the platform and services offer. The first of which was to request that the team working on the S3 upload of new taxonomy data added support for S3 notifications. With the Amazon S3 notification feature, you can enable notifications which are triggered when events take place for an S3 bucket. This is a powerful feature which allows us to act on the events. In my opinion, this is better than the alternative which would require periodically polling of the buckets to detect changes. Polling introduces wasted effort and requests which we can avoid with an event-based design.
We enabled the “new object created” notification for objects created via the Put API. Any time a new file is added to the bucket, a notification is sent. In our case, we decided to send the notification to Amazon SNS. SNS (Simple Notification Service) supports pub/sub messaging. It publishes messages to all subscribed consumers of a topic. This design decision was made since it allows other teams to hook in as subscribers in the future. While my service would be the initial (and only) subscriber, we’ve found that it’s easier to design for multi-consumer scenarios, rather than trying to add it in later.
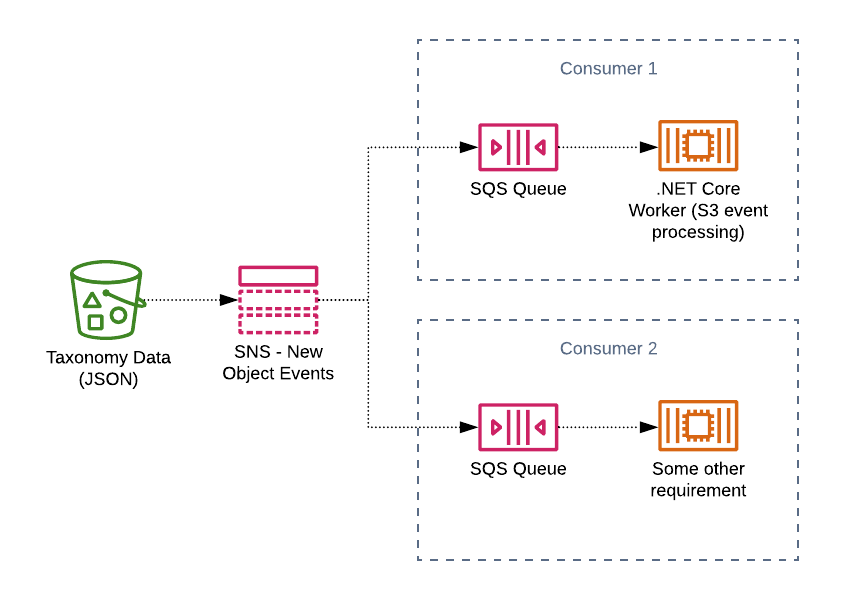
With each microservice we design, developers can include a set of CloudFormation files which describe any owned AWS services. Upon deployment, these files are used to update the infrastructure within our various environments. For the metric expansion processor, I included a CloudFormation file which added an Amazon SQS queue, subscribed to the SNS topic which would publish taxonomy S3 bucket notifications. The plan was to develop a simple .NET Core worker service which would process the bucket event messages from the queue (more on that later).
DynamoDb Design
One of the next decisions I faced was where and how to store my projection. The obvious thought was to use a database. Much of v6 uses PostgreSQL, but I soon ruled this out since it adds a little complexity around managing schema deployments, as well as consuming the data via something like Entity Framework or Dapper. It seemed overkill for my requirement. What I essentially needed was a key-value type store. The service will have a term ID provided by the Jobs API and expect to lookup the related name for the taxonomy entry.
One extra challenge was that for some taxonomy enrichment, we walk the term hierarchy, including all parent terms on the expanded metric. Therefore, a second case was being able to traverse the hierarchy of terms to all direct parents.
In the end, I opted to use Amazon DynamoDb for the data store. DynamoDb is a managed key-value and document database. In the past, I was not a fan of DynamoDb as it seemed confusing and for some designs, quite expensive. More recently, I have given it a second chance and found that with the appropriate forethought around the schema design, it can be a convenient choice. Because DynamoDb is a fully managed service, there is less to consider around management, durability, scaling and security. Those are all included by default.
The first important step when using managed cloud services is to consider the implications of its supported feature set, vendor lock-in and pricing. Having worked with DynamoDb in a limited capacity, I was sure its features would be sufficient for our requirement. For lock-in, this is sometimes a concern. Still, in practical terms, we’ve found it’s better to utilise the tools and managed services for ease of development and not worry about an unlikely migration to a different cloud provider. For the pricing concern, we would first need to estimate the usage, which required some thought about the schema design.
DynamoDb Schema Design
For the design steps, I recommend Alex DeBrie’s DynamoDb book which I recently purchased and read through very rapidly. For this post, I’ll constrain the design details to a relatively high-level. The main steps were to first determine the access patterns for the data and then to design a supporting schema. The main access patterns I determined we needed (and may need in the near future) where:
- Retrieve a term by ID, accessing its metric name.
- Retrieve a term by its ID, including its parent terms, accessing the metric names.
- Retrieve a category by ID, accessing its category name. This is not immediately required, but I designed for it since we may have cases which need this data.
We had already decided that we would ideally use a single table design which would store data for all tenants. Since none of the data is restricted or sensitive, this is a safe and reasonable choice in this case.
Having read Alex’s book and watched a great session “Amazon DynamoDB Deep Dive: Advanced Design Patterns” presented at AWS Re:Invent 2019 by Rick Houlihan; I was aware of the idea of overloading keys. This concept supports storing multiple types of data within the same table, using more generic partition and sort keys to support querying and filtering of the data.
It’s a bit beyond the scope of this post to fully document the design process, but I’ll summarise my steps. For the first time, I opted to use NoSQL Workbench for Amazon DynamoDB to help with my schema design. This tool supports data modelling and visualisation, which I found extremely helpful as I modelled my schema.
Each record in DynamoDb is accessed through a primary key. That key must include a partition key component, which is used by DynamoDb to shard your data. We can optionally include a sort key to form a composite primary key. The sort key can be used to organise related items under the same partition key (an item collection). All data for a partition key is co-located on the same shard, making access very efficient. The partition key must be suitable for sharding the data. It must contain enough unique values that allow data to be equally distributed across shards. The access requirements of each key should be roughly equal across the shards to avoid a hot partition.
I’m storing two main entities in my single table design; categories and terms. I planned to store items for each tenant within the same table. Since we always know the tenant when querying, we can include it in the keys to support our access patterns.
For the partition key, I opted to use a pattern of Entity – Client ID – Entity ID. The client ID is a GUID we use to represent a logical tenant in our services. The entity ID, in this case, is an integer value from the taxonomy data.
Therefore, the partition key for Term ID 100, for tenant (client) ID “823a8c46-8464-4ce6-ae2d-026540681db2” becomes:
“TERM#823a8c46-8464-4ce6-ae2d-026540681db2#100”
Hash characters are used as separators for the elements, a convention I learned from Alex’s book. When querying we have the client and term ID available so we can easily construct the partition key we want to access.
I chose to use the sort key to allow me to store related data for terms, extending the data access options. When storing the term information itself, I would use a sort key matching the partition key. This way, when I just want term information, I can limit the range for the query to only those documents with the matching sort key. I needed to store two related types of data. Zero or more parent terms, when the term is part of a hierarchy, and a one-to-one relationship with the owning category. When adding the category, I used the same value as used for the category partition key. This gives me options when retrieving the data to limit to only sort keys beginning with “CATEGORY” if I only need category data for a term.
For the parent terms, I don’t need a complex hierarchy, but I do need to get the names for all parent terms. I decided to use a sort key with the pattern Parent – Level. The level is not that important besides allowing each parent to have a unique sort key. For a term with a single parent, it would include a sort key in the form “#PARENT#01”. I don’t anticipate a need to sort parents in the hierarchical order right now. Still, this design supports querying in order if I need to. I prefixed the sort key with a hash character here so that when sorting all documents for a partition key, I can read in ascending order to get the parents in hierarchical order.
The schema requirements are pretty straightforward once you get used to the concepts of NoSQL data modelling and the patterns for single table design. A key goal in cost reduction for DynamoDb is to limit the number of reads and writes since billing is directly related to those. The access patterns and design I ended up with help accomplish that goal.
Using NoSQL Workbench, I was able to model my ideas and easily visualise how the data would look with each design. I ended up with the following basic model.
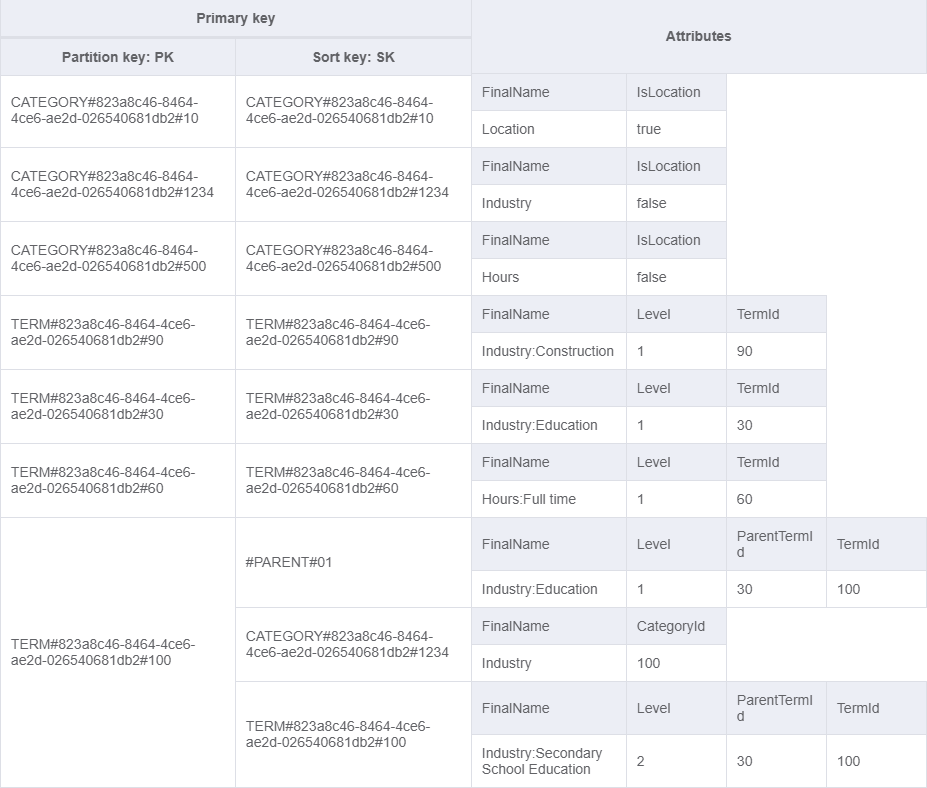
Looking at the last rows, we have a term (ID 100 for client 823a8c46-8464-4ce6-ae2d-026540681db2). There are three items under this single partition key, also known as an item collection. The sort key pattern I described above is used to support storing different item types for the term. This term has a single parent with sort key “#PARENT#01”. Currently, I only need the “FinalName” attribute value which I’d select when expanding the terms related to a job.
The second item represents the owning category. Again I’ve included a category ID attribute. However, a consumer of the data could parse that from the sort key as well.
The final item is the term itself. This uses the same partition and sort key. Hence, in cases where we need only the term itself (and not the parents or category), we query using that computed key for both the partition and the sort key conditions. The “FinalName” is pre-computed for my use case and combines the owning category name and the term name into the format my service requires.
There is some duplication of the data in this design which I decided was reasonable since this data changes rarely and our access patterns are quite simple. The main pattern is getting a term with its parents so we can get all “FinalName” values for the term and its parents. With the current design, we can achieve that with a single query.
With DynamoDb, we are billed based on read and write units. An eventually consistent read for items up to 4KB will consume 0.5 read units. With the design above, we can access a specific term using the GetItem API, which reads the single item from the table. However, we also need the parent details so we can use the Query API to get all items for a partition key in a single billed request. This assumes that the total item size is less than 4 KB.
Taxonomy Notification Processor Design
The next decision was how to process the notifications from S3 when new objects are added. A reasonable managed choice here would be to use AWS Lambda. S3 notifications can directly support Lambda as a destination. They would have been a good fit here for a single consumer scenario. We could also have used an SNS topic in between S3 and Lambda to support multiple consumers. In our case, for a few reasons, I chose instead to use a containerised .NET Core worker service.
The main reason is that our environments already contain Amazon ECS (Elastic Container Service) clusters with provisioned compute (EC2) instances. Adding one extra service to this cluster is low load. It can consume spare compute in the cluster, adding no additional cost. We can dynamically scale the container (task) instances based on the queue size, so we can reduce our instance count to zero when the queue is empty. Other advantages are that we already have templates and patterns for queue processing worker services we can easily re-use. I’ve personally not used Lambda much at all, and that would require some learning to become productive.
The .NET Core worker service template provides a really nice model for building microservices using .NET Core which perform tasks such as queue processing. Worker services support dependency injection, logging and configuration just as we use with our ASP.NET Core APIs. With a worker service, you define one or more background tasks (using a class derived from BackgroundService) which perform your workload.
For queue processors, the pattern I use today is to have two BackgroundService instances running. The first polls for messages on the queue, using long-polling and back-off to limit SQS requests when there is nothing to process. Once a message is received, it is written to a Channel. The second BackgroundService reads from the channel and performs the processing. In my case, this will parse the JSON to establish the term (with parent) data container within the taxonomy. It then writes each item into DynamoDb based on the above schema.
The complete service also needs to access per-tenant configuration to identify the default culture for their site. We record all taxonomy data against the primary culture when recording metrics. The JSON may contain more than one culture for clients who have multi-culture support on their job boards.
I won’t cover the specific details of writing a queue processor in this post. If you have Pluralsight access, I have a course, “Building ASP.NET Core Hosted Services and .NET Core Worker Services” which covers this scenario in depth.
Consumer Code (Querying)
The final piece of the puzzle is to consume the DynamoDb data from the “metric expansion processor” service. This service has a set of term IDs linked to a job and needs to load the final names for each term, including any parent terms. We have designed our DynamoDb table for this primary access pattern, so it’s relatively straightforward. I won’t cover all of the details for querying DynamoDb in this post but as a quick summary of the .NET code. I’ve simplified this a little and removed some error handling and resiliency code.
The preceding code can query for a term, optionally including the parents. First, it builds the “partitionKey” using our known pattern for the keys. We then create the query request. We have two scenarios here. The first request should also get the parents for the term, the second will not.
On line 27, we have the low-level query request for DynamoDb for a term with its parents. The code for building low-level requests is a bit ugly but reasonably straightforward. We are querying a table name provided from the application configuration. Our key expression asks for items matching the partition key we have computed. Since we only need the Sort Key and final name attributes for this requirement, we provide a projection expression. This allows us to limit the amount of data returned by the query to only the attributes we care about. Because we can have multiple items under the same partition key in our schema, we are able to use this query to retrieve them all.
On line 36, we have the query for a term only, without parents. This is basically the same as above, but it adds an extra key expression to limit to only items where the sort key matches our computed partition key. In our schema design, we supported this access pattern for retrieving individual term items from the partition.
In either case, the request is sent to DynamoDb using the service client provided by the AWS SDK for .NET. I’ve taken out error handling, but things you should consider here include the potential for throttled responses if you are breaching a configured read capacity for your table.
Parsing is handled in other methods. The method for parsing a response where we included any parents looks like this:
For each item in the response, we access the sort key attribute. We exclude any which begin with “CATEGORY#” since we don’t need or want the category item. All other items though we do want as these will be the term itself and any parent items. We can read out the string value of the “FinalName” attribute.
Hindsight is a great thing, and since building this service, I’ve realised I could have designed my sort key strategy slightly differently to avoid the need for this client-side filtering. Assuming for now that I don’t care about getting the parent terms in any particular order (which is true today), I could have avoided adding the hash character prefix for the sort key of the parent items. For an example partition key we would then have items sorted as follows:
- CATEGORY823a8c46-8464-4ce6-ae2d-026540681db2#1
- PARENT#01
- PARENT#02
- TERM#823a8c46-8464-4ce6-ae2d-026540681db2#100
With our query, we could then have used a “between” key condition to get sort keys between “P” and “Z” which would filter the category out on the server-side. Since this is a single item and very small, it’s not worth a redesign right now but is something we could consider for the future. As with all software development, you learn as you go, and this is an excellent example of where such learning can occur in retrospect!
That’s pretty much all of the code we need to query DynamoDb for the projected data we need.
Caching
I won’t dive deeply into caching for this post, but a consideration to reduce DynamoDb costs is to utilise a cache for the term data. In our case, we already have a Redis ElastiCache instance with available capacity. Therefore, after loading the term names for a term ID, we also cache a data structure to Redis using the original partition key as the key for the data in the cache.
We can then first check the cache, and if present, use the cached data directly, otherwise we fall back to a DynamoDb query. Since the data is relatively stable, we can cache values for a few days and reduce the number of billed DynamoDb reads. We elected to cache on demand (when accessed) in this iteration since some terms are rarely used. Our taxonomy processor will clear existing entries from the cache when processing a new taxonomy file, which avoids stale data. We could also have chosen to pre-populate the cache with all data in advance, but for now, we have not needed this.
Summary
In this post, I wanted to describe the high-level steps for planning, architecting and building out a .NET Core based microservice architecture. I wanted to focus on using a cloud-native approach and where possible, leveraging managed AWS services. Hopefully, this will help others facing similar design requirements. There are, of course, many ways this could have been achieved. I chose to use services and patterns already in use for other microservices in our organisation. This keeps maintenance headaches much lower since all teams can fundamentally understand how this architecture works.
In written form, the steps sound quite complicated, but most of this is AWS service configuration to set up the notification to a topic and have a queue subscribe to that topic. We manage that with simple CloudFormation templates. The S3 event (taxonomy) processor is a reasonably lightweight service which we deploy to existing compute resources in ECS and scale as required. With the schema design in DynamoDb, we have met our current and potential access patterns using a simple, single-table design.
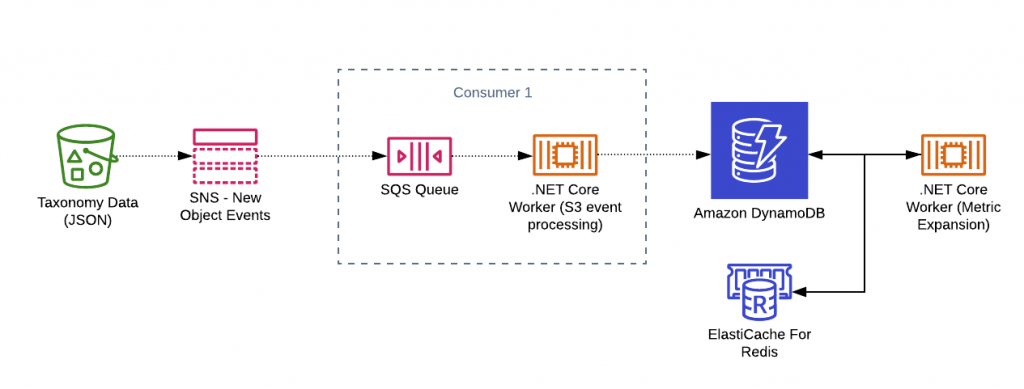
The final architecture looks like this:
Have you enjoyed this post and found it useful? If so, please consider supporting me: