
WARNING: This blog post is informational and relevant to those with an inquisitive mind but should be considered experimental. The code presented here is not suited to most real-world situations, not thoroughly tested and is just for fun!
In this post, I will demonstrate how to create a ReadOnlySequence from some existing data held in multiple arrays. The idea for this post came from a comment on my post, “An Introduction to SequenceReader“. To understand the types and terms used in this post, you may want to read that blog post first.
The question posed to me was:
“How do I create a ReadOnlySequence from two arrays?”
My original answer was:
“It’s not something I’ve looked into as I’ve been a consumer only for now. There’s a constructor which takes a single array or ReadOnlyMemory<t> (ROM), but for multiple arrays of data, I suspect you’ll need to manually create a linked list of ReadOnlySequenceSegment<t> first, to pass into the final ReadOnlySequence. You’ve piqued my interest so I’ll have a look at some point.
What are you doing with the two arrays? My gut is that parsing each in turn would be more efficient anyway as it’s just two you are dealing with. Is performance critical in your case?”
I stand by the points in my reply. For two arrays, manually parsing through them should be fairly simple, without having to resort to creating a ReadOnlySequence. I’d love to know more about the reader’s particular case. Perhaps there is a plausible scenario I’m not thinking of where this might be reasonable.
As an experimental learning exercise, let’s see if and how we can achieve the above requirement. Remember, this is for fun and not likely to be a valid option for real-world scenarios. You can find the code samples used in this blog post in my ReadOnlySequencePlayground repository on GitHub.
Creating a ReadOnlySequence
For this example, let’s start with three arrays containing sequences of integers.
We’ll need to begin by creating a ReadOnlySequence that “wraps” these arrays into a single contiguous representation.
The ReadOnlySequence struct has four constructor overloads which can be used to create an instance.
The last three of these deal with creating a ReadOnlySequence wrapping a single contiguous block of memory, either an array or a ReadOnlyMemory<T>. None of these meet our requirement here. That leaves us with the constructor accepting some ReadOnlySequenceSegment<T> parameters.
So it appears we need two ReadOnlySequenceSegment<T> instances. Let’s take a look at that type. You can view the source in the .NET Runtime repository, and I’ll include it here in its current form.
The first thing to note is that this is an abstract class, so we need to find a concrete implementation we can use. After hunting around in the runtime repository for a while, I found a derived class named BufferSegment within System.IO.Pipelines. Unfortunately, this type has the internal access modifier so we can’t use it here.
It turns out, there are no publicly derived types for ReadOnlySequenceSegment<T>, so we must create our own.
The preceding code is a basic derived implementation of the abstract class. We can create an initial segment using the constructor, passing any type that can be represented as a ReadOnlyMemory<T>. That parameter is used to set the Memory property on the base class.
We also have an Append method which also takes a ReadOnlyMemory<T>. The segments are used to form a linked list structure. Each segment may hold a reference to the next segment in the chain. In this example, our Append method first creates a new MemorySegment<T>. It calculates and sets a value for the RunningIndex property on the new segment. The RunningIndex represents the sum of node lengths before the current node.
Append then sets the Next property on the current segment, with the reference to the new (next) segment we are appending. Finally, it returns the new segment.
This flow may be quite hard to visualise. Hopefully, it will become clearer once we begin to use our MemorySegment<T>.
We begin on line 5 in the sample code above. We create our first segment, passing in the first array. Because an array represents a contiguous region of memory, it confirms to the ReadOnlyMemory<T> argument. We hold onto this first segment in a local variable.
We then call append on the first segment, passing in the second array. This method returns a reference to that second segment. We can immediately chain on the third array using another Append call. This appends the last array as a third and final segment, linked to the second one.
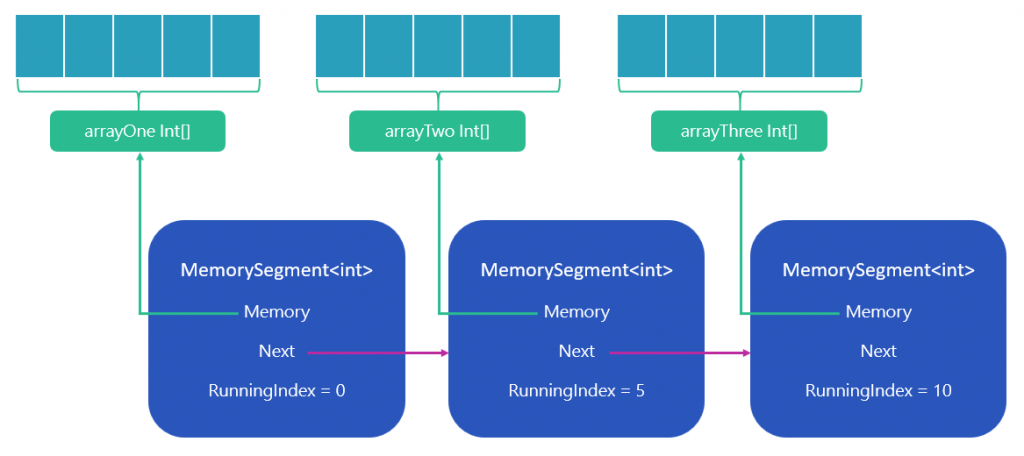
We must hold a reference to the first and the last segments in the chain as we’ve done here. We need those to create the ReadOnlySequence.
On line 4 above, we are now ready to create a ReadOnlySequence<int> using our segments. We pass a reference to the first segment and the start index for the sequence. We want to begin at the start of the first segment, so the index in the second argument is zero.
We then pass the reference to the last segment, followed by the end index. The end index can be used to limit the sequence to a particular index within that final segment. In our case, we want the whole array, so we use the length of the memory referenced by the last segment.
We now have a ReadOnlySequence!
Parsing the ReadOnlySequence
Now that we have a ReadOnlySequence, we can look at how to consume the data from it. I won’t go into quite as much detail for these steps. Our imaginary scenario here will be that we want to access all values from the sequence. However, we want to start from the values after (and including) a value of 6. We need to store those values for future use somewhere in our application code. For this contrived example, we’ll just print the values out to the console once we have them.
We’ll start with a basic implementation and then simplify that slightly. A reminder once again that this is demo code, sufficient to illustrate a point and not necessarily “perfect” code to copy/paste into your production codebase!
We’ll use a SequenceReader here to make working with the ReadOnlySequence a little easier.
First, we need to create somewhere to store the final output of the data that we want. This will be the collection of integer values which appear after (and including) the value 6 in our ReadOnlySequence. Since we’re likely in a high-performance scenario if we find ourselves with a ReadOnlySequence, let’s try and be as efficient as we can.
We need somewhere to store our output values. On line 9, we can use Span<T> since it allows us to apply a handy optimisation. Since we know the maximum possible length of the data, assuming we may read the entire sequence, we can see if it’s safe to store our memory on the stack, rather than heap allocating an array. For this example, I’ve decided that 128 bytes is a reasonable maximum to allow on the stack here. That gives us headroom for 32 integers of 4 bytes each.
Span<T> allows us to represent contiguous memory on either the stack or heap, so we can set the variable of type Span<int> either with memory we allocate on the stack or an array on the heap.
One downside so far is that we determine the space we need based on the total number of values in the original sequence. We are expecting to have a reduced set of values when we parse the sequence, so our output memory is probably oversized. This may push us to allocate an array when the output data could perhaps meet our condition to be stored on the stack. We’ll ignore that for this example.
We can now use the sequence reader on line 16 to position ourselves at the first element in the sequence with a value of 6. From there, we will loop over each value until we reach the end of the sequence. Adding each value to the output memory. We update our position on each loop iteration so we can store the value into the appropriate index.
Once this is completed, we have our output memory populated with data. But, we expect that it’s likely we have not filled the entire memory region with data. So on line 27, we slice the Span<int> from the start until the position of the last element we added.
We now have a new Span<int> representing the memory, and therefore values, that we care about from the original sequence. In a real situation, we’d likely want to do some further processing, but for this sample, we’ll just print out each value to the console.
Parsing the ReadOnlySequence (Take Two)
Thanks for David Fowler for a quick chat we had about my demo code. He pointed out that I could simplify the example, which then led me to this refactored code that I’m about to share with you.
This time, we first check if we have the value of 6 anywhere in our sequence. If we don’t, then we exit from the method immediately.
If we find an element with the value of 6, we can simply slice the entire sequence from that position. We do that on line 10 in the above code. At this point, we have another ReadOnlySequence representing the data we care about. In this example, that sequence is still backed by the last two segments we created since that’s where the data resides.
Since we now know the exact length of the final data, we can use the same approach as applied earlier to create a Span<int> backed by some memory large enough to hold the output data. Again we try to use the stack if there are 32 or fewer integers in the final data. This time, we are sure of the final length of the data that we want to output so we avoid oversizing the memory we need. This makes it more likely we’ll be able to stack allocate for small amounts of output data.
We then loop over the data and print the values to the console.
Downsides of These Approaches
We’ve now answered and implemented the question from the original comment.
“How do I create a ReadOnlySequence from two arrays?”
But just because you can do something in code, doesn’t mean you should. There are some things I’m not happy about in this sample.
Code Verbosity
First and foremost, it’s pretty verbose and required a moderate amount of code to first create a ReadOnlySequence and then parse through it. Given that the original question mentioned two arrays, I’m reasonably sure we could parse each of those, in turn, using a Span<T> based approach. Depending on the actual scenario, even that may be overkill, and a more straightforward technique of iterating over each array in turn, would probably suffice. Without knowing the exact scenario, the size of the arrays or the performance constraints, it’s impossible to say for sure which technique is best.
Memory Allocations
The second issue with this code concerns optimisation. While I’ve made reasonable efforts to parse the ReadOnlySequence with zero allocations, there remains an issue around creating the ReadOnlySequence in the first place.
Because we had multiple source data inputs, we were forced into using the constructor taking two ReadOnlySequenceSegment<T> parameters. Before we can create the ReadOnlySequence, we need a “linked list” of the memory segments. To achieve that, I created a class, MemorySegment<T>, which provided a fundamental implementation of the abstract ReadOnlySequenceSegment<T> class.
We then had to create three segments for each of the arrays, linking them together through our Append method. MemorySegment here is a class, which will result in a heap allocation for each instance. I measured that overhead, and it comes to 48 bytes per segment, a total of 144 bytes for my three segments. For a limited number segments, this might be reasonable, but where I would see this being applied more realistically, you’ll likely have many more segments. This allocation overhead, just to achieve the creation of a ReadOnlySequence may not be reasonable.
Imaging for a moment that we do have perhaps 200 arrays that we’d like to link into a ReadOnlySequence, a better approach would be to use a Pipe from System.IO.Pipelines. The Pipe concept would support this scenario quite reasonably. Firstly, you can read and write to a pipe independently in a thread-safe way. Therefore you could start two concurrent Tasks, one writing into the pipe from each array in turn, and another, reading through the sequence as data was flushed through.
A second advantage is that the pipe is heavily optimised on our behalf and pools the buffers and the link list nodes (segments) required to operate on the data efficiently. If the desired outcome were to access a ReadOnlySequence from a starting point of many independent arrays, I would indeed start with a Pipe. This would be easier than managing the creation and linking of each segment in my own code.
Summary
In this post, we took on a theoretical exercise and learned a little more about the ReadOnlySequence<T> type. I stand my original answer to the comment on my “An Introduction to SequenceReader” blog post. I don’t think the code I’ve shown is a sensible choice for the actual problem being presented.
However, I love questions like this since it made me realise, I hadn’t actually considered how a ReadOnlySequence is created. By investigating this with a small sample, I learned more about how this type behaves, which I consider as time well invested. I hope you found reading this post equally useful or at least interesting!
I’ll end with one final reminder, please don’t put this code blindly into production. There are sure to be dragons!
Have you enjoyed this post and found it useful? If so, please consider supporting me: