
In the prior two posts in this series we took a look at the main Docker terminology and looked at creating a basic dockerfile to define a Docker image containing an ASP.NET Core API application. In this post I want to switch it up a bit and spend a little time sharing a specific practical reason that led our team to start using Docker in our development flow. This was our first step in the Docker journey that we now find ourselves on and expands on the summary I introduced in part 1.
Why we started using Docker
Warning! This post has no code examples. Instead what I’ll be describing is a real-world situation that led us to start using Docker for our new project. I want to highlight why Docker was a good choice given our requirements and hopefully you’ll find cases in your work where it may be relevant to consider Docker yourself. I think it’s useful to share this story, while there’s a lot of excitement about Docker and some clear benefits, it’s useful to reflect on a practical advantage it brought us with very little effort. This is simply the start of the journey and I will be expanding on how our use evolved as the series continues. I hope you find this part useful, but don’t worry, I won’t be offended if you want to skip onto the docker-compose examples in part 4! See, I even provided a link!
As I explained in the first post, our new greenfield project at work kicked off in 2016. We needed to build a system to provide data analytics over a very large data set of event based data. I won’t cover the architecture of the back end components at this stage. For this post it’s the front end where I want to demonstrate the first benefit we were able to gain from using Docker.
At work, our front end and back end teams are split and work on their areas of expertise accordingly. On our current platforms, we have an in-house MVC framework which uses a custom templating language for the front end pages. When our front end developers need to perform work on the UI, they must pull down and update the main platform code on their devices in order to spin up the site locally. Given that this is a large platform, the size of the changes they need to pull could be fairly large. In order to work with the site, they must compile the code and run it locally, which, as this platform is built on the full .NET framework, requires Windows and IIS. Therefore, each developer, most of whom use a Mac, must have a Windows VM installed, or access to a Remote VM in order to work with the code.
Over time this flow has evolved to make the process as efficient as possible but it’s still not an ideal solution. With this new project we had the opportunity to try a new more modern approach. Given that the UI for this analytics style application was very interactive, we decided that it made sense to develop a SPA style front end. This had the benefit that it enabled the front end developers to choose a technology that suited them. After a bit of research they landed on Vue.js.
In order to support the front end SPA, we agreed that we would provide a number of REST API services, each providing a specific, bounded functionality. We could have chosen to build one larger, all-encompassing API application, but decided that the smaller APIs made scaling each component much easier. Scaling would be dependent on their own unique load and allow us to better use the resources of the server. It also means we can keep the code separated and hopefully easier to maintain. We can change each component independently and work more rapidly.
We ended up with a design that included 3 web facing API services, each backed by its own database. We have a user API which handles authentication and authorisation for the application, as well as other user management services. We have a report API that enables the creation and running of reports and we have a schedule API used for creating scheduled reports and managing downloads. Finally, we have a back end API which is responsible for querying over ElasticSearch, processing the data and returning the resulting data. This query API is used by both the reporting API and our offline back end scheduled report service.
Here is a diagram showing the main components our of front end services architecture:
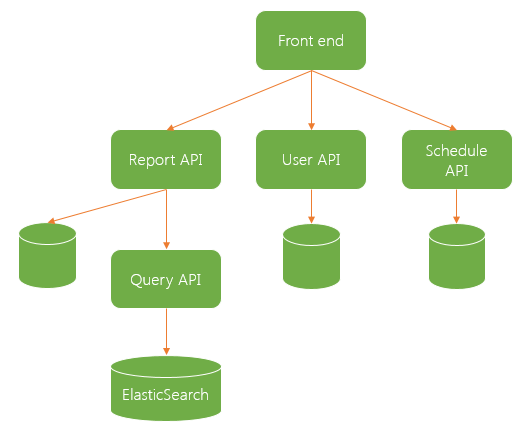
At the time we were creating our architecture, ASP.NET Core was in RC and we took a brave but in the long run, good decision to use the new framework to develop our APIs. Not only were we interested in the performance and framework improvements, but we also knew we could begin to take advantage of the cross platform nature of .NET Core to allow us to look at different hosting options. Having recently started moving our systems into AWS we initially were considering the possibility of using Linux VMs to host the APIs.
As we pursued this path, another benefit of this decision came to light. Now that we were cross platform and planning to target Linux for hosting, we realised we could start to look at Docker and containerisation as part of our workflow. This opened up some new possibilities and after talking through the concept we realised that we could make development for the front end team much easier by providing Docker images to run the API code. The big change this presented is that they would no longer need to run Windows in order to build the UI for the platform and they would no longer need Visual Studio in order to build the source code.
A downside of splitting things into smaller microservices is that in order for a system to function, you often need multiple things running together at the same time. In our case, each of the 4 main API services needed to be running for the front end to be able to fully function. Each of those also needed a database server, we had chosen Postgres, to support the data storage requirements. Spinning up all of these parts needed a little coordination.
When we started looking at Docker we realised that we could solve this problem using docker-compose files. Docker-compose provides a simple way to start multiple containers with a single command. In our case, each service is a separate Visual Studio solution and repository. This allows us to develop, build and deploy each part of the system individually. As long as the public facing API endpoints do not change then we can update the internals of each API with no impact on the other parts of the system. In each solution we include a dockerfile to describe a Docker image that that will run the API service. These dockerfiles initially started very much like the example I showed in part 2 of this series. We have since gone on to optimise the files and I plan to explore that in a future post.
In addition to the dockerfiles we also provide a docker-compose file which, with a single command, can be used to build all of the required images. With a second command we can start all of the containers needed to support the front end. Our first iteration of the front end workflow relied on the front end developers pulling the latest source from each repository. They could then use the docker-compose build command which triggered image creation. Since the build is happening inside the Docker containers, they do not need to run Windows or even have the .NET SDK installed on their Macs. As part of the solution, we also utilised a public Docker image for Postgres as one of the services defined within our docker-compose file. This means that the front end team do not need to install Postgres on their own device either. Other than Docker, there are no dependencies to run the back end services required to develop the front end website. With these steps we had removed a barrier for the front end team and very much simplified our development process.
In the second iteration that we are now working on for the front end workflow we are providing the front end team with a new docker-compose file which pulls images from a private container registry running in AWS ECR. With this change there is no need for the front end developers to ever pull or update the source for the components they need. Instead, the compose file will pull the latest available images from the registry and have them up and running extremely quickly. We’re still investigating and testing how we want to finalise this part of our development workflow so it’s something I’ll share in a future post.
The same process proved really useful for QA and testing as well. Anyone involved with testing the system could pull the components down and run the full system in isolation on their machine. The front end website is also containerised and in this case we even used an ElasticSearch Docker image to allow a full end to end system to be started and tested on a machine, with few external dependencies. The dependencies we could not containerise were things such as access to Amazon AWS SQS and S3 for example.
One by-product of leveraging Docker for the front and back end developer flow is that we can start to eliminate the “it worked on my machine” arguments. By loading everything inside Docker we get to a place, where everyone is working on an identical, repeatable environment. Because our image contains all of the dependencies, we can be sure we have matching versions and configuration every time it is run. We don’t have to ask developers to maintain correct versions of dependencies on their devices either.
Other Posts In This Series
Part 1 – Docker for .NET Developers Introduction
Part 2 – Working with Docker files
Part 3 – This post
Part 4 – Working with docker-compose and multiple ASP.NET Core microservices
Part 5 – Exploring ASP.NET Runtime Docker Images
Part 6 – Using Docker for Build and Continuous Deployment
Part 7 – Setting up Amazon EC2 Container Registry
Have you enjoyed this post and found it useful? If so, please consider supporting me:
Thanks for sharing this valuable real life experience. Looking forward for more. Cheers.
Thanks Mustakim
Loved the article. Thanks for sharing, I just started looking into Dockers and looking forward for more.
Thanks for the feedback. I’m glad you’re finding the content helpful.